
IndexFiguresTables |
Dong Kook KimNoise Contrastive Estimation of Coupled Energy-Based Model for Anomaly DetectionAbstract: In this paper, a new coupled energy-based model (CEBM) for anomaly detection and noise contrast estimation (NCE) technique for learning it are presented. The structure of CEBM consists of the product of two unnormalized probability distributions, each of which is defined by an energy function with a deep neural network. We derive the objective function of NCE by using one distribution of CEBM as a noise distribution and present a parameter update method using the gradient descent method. An experiment using ECG, UNSW and MNIST/Fashion-MNIST is conducted to evaluate the anomaly detection performance of the proposed technique. As a result of the experiment, the CEBM learned with the proposed NCE shows higher F1-score than the existing EBM sinall datasets. Keywords: energy-based model , noise contrastive estimation , anomaly detection , deep neural networks Ⅰ. 서 론에너지 기반 모델(Energy-based Models, EBMs)[1-4]은 기계학습 비지도 학습(unsupervised learning) 분야에서 널리 사용되는 하나의 모델로 최근 관련 연구가 활발히 진행되고 있다. EBM은 심층신경망을 사용하는 에너지 함수(energy function)를 통해 입력 데이터의 분포를 모델링하는 확률적인 기법이다. 에너지 함수로 복잡한 심층신경망을 사용하기 때문에 EBM는 확률분포에 대한 비정규화된(unnormalized) 파티션 함수(partition function)을 갖는 것이 특징이다[2]. 이러한 EBM의 구조로 인해 다양한 데이터의 분포를 효과적으로 모델링할 수 있어 특징학습, 이미지 생성, 밀도추정 그리고 이상탐지 (anomaly detection) 등과 같은 다양한 분야에 응용되고 있다[5-7]. EBM은 심층신경망을 기반으로 고차원의 복잡한 데이터의 분포를 정밀하게 표현할 수 있어 이상탐지 분야에서 널리 사용되고 있다[5]-[8]. 특히 정상 데이터만을 사용하여 분포를 모델링하고 이 분포를 이용하여 정상/비정상을 탐지하는 준지도(semi-supervised) 이상탐지에 EBM 구조가 매우 적합하다[8]. 정상 데이터의 수집은 상대적으로 쉽지만, 이상 데이터의 획득이 어렵고 데이터 labeling의 큰 노력이 필요하므로 준지도 이상탐지에 autoencoders(AEs)[9], generative adversarial networks(GANs)[10]과 함께 EBM이 널리 쓰이고 있다. EBM는 비정규화된 분포 형태로 인하여 데이터에 대한 정확한 우도비(likelihood) 계산이나 데이터 생성 과정에 많은 계산량이 필요하여 학습이 매우 어려운 것으로 알려졌다[2]. EBM의 파라미터 학습기법에는 Markov chain Monte Carlo(MCMC)[11]에 기반한 최대 우도비(Maximum-Likelihood ML), 스코어 매칭(Score Matching, SM) 그리고 잡음대비추정(Noise Contrastive Estimation, NCE) 등이 있다[2]. ML 학습은 파티션 함수의 문제점을 극복하기 위해 MCMC를 사용하여 데이터를 생성하고 이를 학습에 이용하는 기법이다. 그러나 이는 데이터 생성 과정에 매우 많은 계산량이 요구되는 단점이 있다. 이러한 단점을 극복하기위해 학습 데이터를 초기값으로 하여 짧은 MCMC를 수행하는 contrastive divergence(CD)[4] 기법이 사용되고 있다. SM[2,12-14] 기법은 파티션 함수를 계산하지 않고 EBM을 학습할 수 있는 기법이다. SM의 목적함수는 데이터 분포와 모델 분포 사이에 Fisher divergence라 불리는 두 분포의 로그 미분값 차이의 유클리드 거리(Euclidean distance)에 의해 정의된다. 이 기법의 장점은 MCMC와 같은 표본화 과정이 필요 없다는 것이다. 그러나 목적함수 내의 2차 도함수 때문에 많은 계산이 요구되는 단점이 있다. NCE[2,15-18]은 알려진 잡음분포와 EBM을 대비하여 학습하는 기법이다. NCE의 특징 중의 하나는 파티션 함수를 파라미터로 취급하여 학습 중에 추정할 수 있으며, 이에 따라 데이터의 우도비 계산이 가능하다는 것이다[15]. 그러나 NCE 단점은 잡음분포의 선택에 따라 성능이 매우 큰 영향을 받는 것이다. 잡음분포가 데이터 분포와 완전히 다른 경우는 학습이잘 안되지만, 근사적으로 가까울 때 더 좋은 성능을 나타낸다[14]. 잡음분포를 데이터 분포와 가깝게 학습하는 기법들이 제안되었지만. 사용되는 분포의 형태가 매우 제한적이라는 단점을 갖는다[16-18]. 본 논문에서는 두 가지 확률분포를 결합한 새로운 EBM 구조와 이를 NCE 기법으로 학습하는 알고리즘을 제안한다. 두 가지 확률분포는 비정규화된 EBM 구조를 가지며, 하나는 변별기(discriminator)로, 다른 하나는 NCE의 잡음분포의 역할을 수행한다. 각각 EBM의 에너지 함수는 여러 형태의 심층신경망에 의해 정의된다. 제안된 구조의 NCE 학습을 위해 GAN과 비슷한 최소최대(minmax) 손실함수를 유도하고 gradient descent(GD) 알고리즘에 근거한 파라미터를 갱신법을 제시한다. 제안된 학습기법의 성능을 평가하기 위해 준지도 이상탐지 실험을 수행한다. 이상탐지 실험을 위해 ECG[19], UNSW[20] 그리고 MNIST[21]/Fashion-MNIST[22] 데이터 셋을 사용한다. 실험 결과 제안된 기법은 모든 데이터 세트에서 AE, ML와 SM 기반 EBM보다 더 높은 F1-score 성능을 나타내었다. 또한 다른 기법과의 성능 비교를 통해 제안된 CEBM과 NCE 학습기법이 이상탐지에 매우 효과적임을 나타낸다. 본 논문의 본론 Ⅱ장에서는 EBM과 NCE 기법을 소개하고, 결합 EBM과 이를 NCE로 학습하는 알고리즘을 제시한다. III장에서는 실험 및 결과를 나타내고, Ⅳ에서는 결론을 맺는다. Ⅱ. 본 론2.1 EBM과 학습기법이 장에서는 EBM과 이를 학습하기 위한 NCE 기법을 간단히 소개한다. 확률변수 x을 입력신호라 하고, x의 모델 분포를 파라미터 θ를 갖는 [TeX:] $$p_\theta(x)$$라 하자, EBM은 [TeX:] $$p_\theta(x)$$를 다음과 같은 Boltzmann 분포로 정의한다[1,2].
여기서 [TeX:] $$E_\theta(x)$$는 에너지 함수이며, 파라미터 θ를 갖는 심층신경망에 의해 정의된다. [TeX:] $$Z_\theta=\int \exp \left\{-E_\theta(x)\right\} d x$$는 θ의 함수로 정규화 상수 또는 파티션 함수라 한다. EBM의 [TeX:] $$p_\theta(x)$$가 주어진 경우 이로부터 샘플들은 MCMC 기법을 사용하여 생성한다. EBM을 휘한 가장 일반적인 MCMC 알고리즘은 stochastic gradient Langevin dynamics (SGLD) 기법이며, 아래와 같이 반복적인 업데이트 식을 사용된다[11].
(2)[TeX:] $$x_t=x_{t-1}-\alpha_t \nabla_x E_\theta\left(x_{t-1}\right)+\sqrt{2 \alpha_t} \epsilon_t, \epsilon_t \sim N(0, I)$$여기서 [TeX:] $$\alpha_t \gt 0$$은 step-size이며, N(0,I)은 평균 0, 공분산이 단위행렬 I인 다변수 정규분포이다. 샘플은 초기값 [TeX:] $$x_0$$에서 시작하여 단계별로 반복적인 가산적인 가우시안 잡음을 더한 후 에너지 함수의 경사도 값을 통해 갱신된다. 다양한 가정하에서 매우 작은 [TeX:] $$\alpha_t$$와 큰 시간 T에 대해 [TeX:] $$x_T$$의 분포가 [TeX:] $$p_\theta(x)$$에 수렴하는 것으로 알려졌다[11]. EBM을 학습하기 위한 대표적인 방법으로 MCMC 기반 ML, SM 그리고 NCE 기법이 있다[2]. ML와 SM 기법이 가장 많이 사용되지만, 최근에 NCE 기법이 그 장점 때문에 주목을 받고 있다[2, 15-18]. NCE의 핵심 아이디어는 EBM의 학습이 이미 알려진 잡음분포와 대비하여 이루어지는 것이다[2]. [TeX:] $$p_{\text {data }}(x)$$를 데이터 분포, [TeX:] $$p_\theta(x)$$를 EBM 그리고 [TeX:] $$p_n(x)$$를 잡음분포라 하자. 이때 잠음분포는 N(0,I)와 같이 간단하며, 효율적으로 분포 값을 계산할 수 있고 또한 샘플링할 수 있는 분포를 사용한다. NCE 학습은 관측 데이터와 잡음 분포로부터 생성된 데이터를 서로 대비시키는 이진 분류기(logistic regression)를 사용하여 두 데이터가 최대 분류가 되도록 파라미터를 추정한다. 관측 데이터와 잡음 데이터에 대한 선행 확률이 같다고 가정하면, NCE의 목적함수는 아래와 같이 주어진다[2,15].
(3)[TeX:] $$\begin{aligned} & V(\theta) \\ & =E_{p_{\text {data }}(x)}\left[\log \frac{p_\theta(x)}{p_\theta(x)+p_n(x)}\right]+E_{p_n(x)}\left[\log \frac{p_n(x)}{p_\theta(x)+p_n(x)}\right] \end{aligned}$$다른 학습기법에 비해 NCE의 특징은 정규화 상수 [TeX:] $$Z_\theta$$를 파라미터로 학습이 가능하다는 것이다. 위의 목적 함수를 최대화하도록 파라미터를 학습하면 [TeX:] $$p_\theta(x)$$가 데이터 분포 [TeX:] $$p_{\text {data }}(x)$$를 근사화하는 것으로 알려져 있다. NCE의 단점은 성능이 잡음분포 [TeX:] $$p_n(x)$$의 선택에 따라 매우 큰 영향을 받는다는 것이다. [TeX:] $$p_n(x)$$은 다음 3가지 조건을 만족하도록 선택된다[15][18]. (i) 정규화된 분포함수로 분포 값의 계산이 가능해야 하며, (ii) 이 분포로부터 샘플링이 쉬어야 하며, (iii) 데이터 분포와 비슷한 형태를 가져야 한다는 것이다. (i)와 (ii)을 조건을 만족해야 목적함수 식(3)의 계산이 가능하며, (iii)의 조건을 만족해야 좋은 성능을 나타내게 된다. 특히 이미지와 같은 고차원의 데이터에 대해 단순한 가우시안 분포를 잡음분포로 사용하는 경우 학습이 어려운 것으로 알려졌다[15]. 따라서 NCE 기법으로 효과적으로 학습하기 위해 EBM의 구조와 잡음분포 추정에 관한 연구가 요구되고 있다. 2.2 결합 EBM과 NCE 학습이 단원에서는 EBM의 새로운 형태인 결합 EBM과 이를 학습하기 위한 NCE 기법을 제안한다. 새롭게 제시하는 결합 EBM의 구조는 비정규화된 두 개의 분포, [TeX:] $$p_\theta(x) \text { 와 } q_\phi(x)$$의 곱으로 정의되는 확률모델이다.
여기서 [TeX:] $$p_\theta(x) \text { 와 } q_\phi(x)$$는 각각 파라미터 [TeX:] $$\theta \text { 와 } \phi$$을 갖는 비정규화된 EBM 구조, 즉 [TeX:] $$p_\theta(x) \propto e^{-D_\theta(x)}$$와 [TeX:] $$q_\phi(x) \propto e^{-G_\phi(x)}$$을 갖는다고 가정한다. 정규화 상수 [TeX:] $$Z_{\theta, \phi}$$는 확률분포의 정규화 조건을 만족하기 위해 [TeX:] $$Z_{\theta, \phi}=\int p_\theta(x) q_\phi(x) d x$$이며, [TeX:] $$\theta, \phi$$의 함수이다. CEBM의 분포 [TeX:] $$h_{\theta, \phi}(x) \text { 는 } p_\theta(x) \text { 와 } q_\phi(x)$$의 결합 형태로, 각각의 에너지 함수 [TeX:] $$D_\theta(x) \text { 와 } G_\phi(x)$$가 심층신경망으로 구성된다. 따라서 이를 결합 에너지기반 모델(Coupled EBM, CEBM)이라 부른다. 이러한 CEBM의 특징은 서로 다른 역할을 수행하는 분포들을 결합함으로써 데이터를 효과적으로 모델링할 수 있고, NCE 학습과정이 더 단순하게 수행되는 장점이 있다. 여기서 CEBM 구조에 기반하여 [TeX:] $$h_{\theta, \phi}(x)$$가 데이터분포 [TeX:] $$p_{\text {data }}(x)$$에 근사화되도록 파라미터 [TeX:] $$\theta, \phi$$를 추정하는 NCE 기법을 제시한다. 이를 위해 본 논문에서는 CEBM의 일부인 [TeX:] $$q_\phi(x)$$를 잡음분포로 사용한다. 이에 따라 모델과 잡음분포의 파라미터 [TeX:] $$\theta \text{ 와 } \phi(x)$$를 식(3)에 근거하여 반복적인 방법에 따라 학습한다. 이때 NCE는 GAN과 비슷한 최소최대 손실함수, [TeX:] $$\min _\phi \max _\theta V(\theta, \phi)$$을 사용하고, 다음 식으로 유도된다[17][18].
(5)[TeX:] $$\begin{aligned} & V(\theta, \phi) \\ & =E_{p_{\text {data }}(x)}\left[\log \frac{h_{\theta, \phi}(x)}{h_{\theta, \phi}(x)+q_\phi(x)}\right]+E_{q_\phi(x)}\left[\log \frac{q_\phi(x)}{h_{\theta, \phi}(x)+q_\phi(x)}\right] \\ & =E_{p_{\text {data }}(x)}\left[\log \frac{p_\theta(x)}{p_\theta(x)+1}\right]+E_{q_\phi(x)}\left[\log \frac{1}{p_\theta(x)+1}\right] \\ & =E_{p_{\text {data }}(x)}\left[\log \sigma\left(-D_\theta(x)\right)\right]+E_{q_\phi(x)}\left[\log \left(1-\sigma\left(-D_\theta(x)\right)\right)\right] \end{aligned}$$여기서 [TeX:] $$\sigma(x)=1 /\left(1+e^{-x}\right) .$$는 sigmoid 함수이다. 위의 첫 번째 식은 식(3)에서 [TeX:] $$p_\theta(x)$$ 대신에 [TeX:] $$h_{\theta, \phi}(x)$$를, [TeX:] $$p_n(x)$$ 대신 [TeX:] $$q_\phi(x)$$를 대입함으로 얻을 수 있다. 두 번째 식에서는 [TeX:] $$q_\phi(x)$$가 상쇄되며, 마지막 식은 간단한 sigmoid 함수식에 의해 정의된다. 식(5)은 변별기와 생성기(generator)을 갖는 GAN 손실함수와 매우 비슷하다[10]. [TeX:] $$D_\theta(x)$$는 학습 데이터 샘플과 [TeX:] $$q_\phi(x)$$로부터 생성되는 샘플을 판별하는 변별기 역할을 수행하며, [TeX:] $$G_\phi(x)$$는 데이터 분포를 근사적으로 추정하는 잡음분포의 역할을 수행한다. 따라서 CEBM은 두 가지 역할을 수행하는 모델들이 하나로 결합된 구조를 갖는 것이 특징이다. 또한 손실함수에서 [TeX:] $$q_\phi(x)$$의 분포 값 계산을 필요하지 않아 잠음분포의 다양한 선택이 가능하다는 장점이 있다. 그러나 [TeX:] $$q_\phi(x)$$을 잡음분포로 사용함으로써 샘플링이 더 복잡해지는 단점이 있다. 샘플링 과정은 [TeX:] $$q_\phi(x)$$의 에너지 함수 [TeX:] $$G_\phi(x)$$ 구조와 MCMC 기법에 의존한다. 본 논문에서는 샘플링을 위해 식(2)의 SGLD와 더불어 아래와 같은 에너지 함수 [TeX:] $$G_\phi(x)$$를 사용한다[6].
(6)[TeX:] $$q_\phi(x)=e^{-G_\phi(x)}, G_\phi(x)=\frac{1}{2}\left(x^T x-f_\phi^T(x) f_\phi(x)\right)$$여기서 [TeX:] $$F_\phi(x)$$은 여러 개의 출력 노드를 갖는 심층신경망을 나타낸다. 식(2)의 SGLD를 이용한 샘플링을 수행하기 위해 x에 대한 [TeX:] $$G_\phi(x)$$의 미분이 요구된다. 식(6)의 에너지 함수는 아래와 같은 미분값을 갖는다.
여기서 [TeX:] $$\nabla_x f_\theta(x)$$은 Jacobian 행렬, T는 전치(transpose)를 나타낸다. 식(7)을 기반으로 본 논문에서는 계산량 감소를 위해 CD-1 알고리즘[4]과 비슷하게 학습 데이터 [TeX:] $$x_0$$를 초기값으로 하는 간단한 1-step SGLD을 사용한다.
(8)[TeX:] $$x=\nabla_x^T f_\theta\left(x_0\right) f_\theta\left(x_0\right)+\gamma \epsilon, \epsilon \sim N(0, I)$$위 식은 식(2)에 식(7)를 대입하고 [TeX:] $$\alpha_t=1, \gamma=\sqrt{2 \alpha_t}$$로 설정하여 얻게 된다. 실험을 통해 위와 같은 샘플링 과정이 매우 잘 동작하는 것을 알 수 있다. 제안된 CEBM에 대한 NCE 학습 알고리즘은 다음과 같다. Ⅲ. 실 험이 장에서는 제안된 CEBM의 성능 평가를 위해 준 지도 기반 이상탐지 실험을 수행하였다. 이상탐지를 위해 3가지 데이터 세트, ECG, UNSW 그리고 MNIST/Fashion-MNIST를 이용하였다. AE, ML 기반 EBM, SM 기반 EBM 그리고 기타 모델 등을 사용하여 성능을 비교하였다. 이상탐지 성능 평가의 척도로 F1-score[8]를 이용하였다. 3.1 ECGECG5000[19]은 20시간 길이의 심전도 데이터로 각 하트 비트를 추출하고 보간법을 사용하여 각각의 길이를 같게 전처리하였다. 심전도 전체 데이터 수는 5,000개이며, 각 데이터는 140개의 실수 값으로 구성된다. 모든 데이터는 [0,1] 사이로 minmax 정규화되었다. 각 심전도는 1(비정상) 또는 0(정상)으로 레이블링되고 학습에는 정상 1639개, 테스트에는 정상/비정상 1000개를 사용하였다. CEBM의 훈련을 위해 학습률 η=0.0001을 갖는 Adam optimizer을 이용하였고, batch size 100, 그리고 SGLD 파라미터로 γ=0.1를 설정하였다. Epoch은 최고의 성능이 나오도록 선택되었다. CEBM의 두 에너지 함수 [TeX:] $$D_\theta(x) \text { 와 } G_\phi(x)$$을 구성하는 신경망은 완전연결신경망경망(Fully-Connected NN, FCNN)을 사용하였다. [TeX:] $$D_\theta(x) \text { 와 } G_\phi(x)$$의 신경망은 같은 층으로 구성하였고, 3층의 경우에 각각의 노드 수는 (140-1024-1024-1)와 (140-1024-1024-512)를 사용하였다. 먼저 CEBM의 이상탐지 특성을 파악하기 위해 정상과 비정상 데이터에 대한 [TeX:] $$D_\theta(x) \text { 와 } G_\phi(x)$$ 값에 대한 히스토그램을 사용하였다. 그림 1은 [TeX:] $$D_\theta(x)$$(위)와 [TeX:] $$G_\phi(x)$$(아래) 값에 대한 정상과 비정상 데이터의 히스토그램과 최적의 임계값을 나타낸다. 이때 [TeX:] $$D_\theta(x)$$의 평균과 분산은 정상은 (5.2, 1.1), 비정상은 (2.7, 0.5)이며, 최적의 임계값은 3.86이다. [TeX:] $$G_\phi(x)$$는 각각 (-8.876, 0.027), (-8.907, 0.016) 그리고 –8.88이다. 그림 1에서 정상과 비정상의 [TeX:] $$D_\theta(x)$$ 값들은 변별력 있게 분포하지만, [TeX:] $$G_\phi(x)$$는 많은 부분에서 중첩해서 나ㅏ났다. 이는 [TeX:] $$D_\theta(x)$$가 데이터를 잡음분포와 대비하여 변별력 있게 학습할 결과라고 할 수 있다. 따라서 CEBM의 성능평가 척도로 [TeX:] $$D_\theta(x)$$ 값을 임계값과 비교하여 정상과 비정상을 판별하였다. 임계값은 훈련 데이터의 [TeX:] $$D_\theta(x)$$의 평균값을 중심으로 최적의 값을 선택하였다. 그림(Fig.) 1. CEBM의 두 에너지 함수에 대한 히스토그램, (위) [TeX:] $$D_\theta(x)$$ (아래) [TeX:] $$G_\phi(x)$$ (Histogram of the two energy functions of CEBM, (Top) [TeX:] $$D_\theta(x)$$ (Bottom) [TeX:] $$G_\phi(x)$$.) 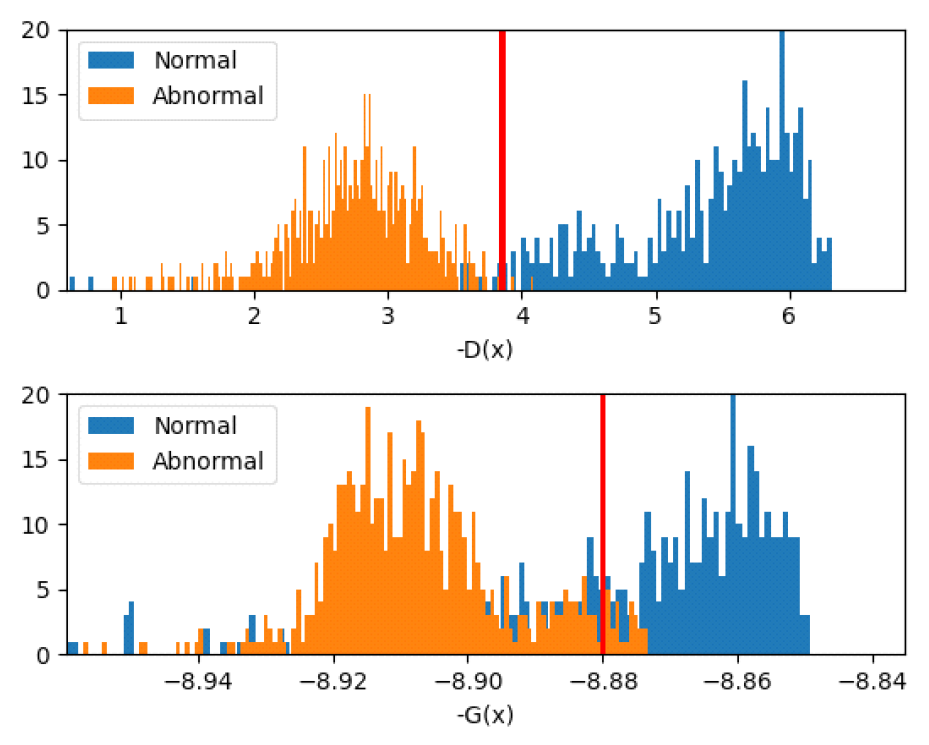 그림 2는 ML와 SM 기반 EBM 그리고 제안된 NCE 기반 CEBM에대한 은닉층 수에따른 성능을 나타낸다. 3층일 때 모든 기법이 가장 높은 성능을 나타내었고, CEBM은 2층과 3층에서 비슷한 결과를 보였다. 제안된 NCE 기반 CEBM은 ML과 SM보다 모든 층에서 더 높은 성능을 나타내었다. 표 1에서 제안된 기법과 AE, VAE 그리고 transformer 기법의 성능을 추가로 비교하였다. 표에서 살펴보듯이 제안된 기법은 AE와 VAE[23] 보다 높은 96.53%의 F1-score를 나타내었다. 이때 CEBM의 precision과 recall은 각각 93.62%와 99.64%를 기록하였다. 그러나 최근에 제안된 더 복잡한 구조를 갖는 transformer[24]에 비해 더 낮은 성능을 나타내었다. 따라서 ECG 실험에서 제안된 기법이 최근 모델인 transformer 기법에 비해 더 낮지만, 비슷한 구조를 갖는 EBM과 AE/VAE 기법들에 비해 이상탐지에 더 효과적임을 알 수 있다. 그림(Fig.) 2. ECG에서 은닉층 수에 따른 EBM의 학습기법에 대한 F1-score (%) (The F1-score(%) on the learning methods of EBM according to the number of hidden layers in ECG.) 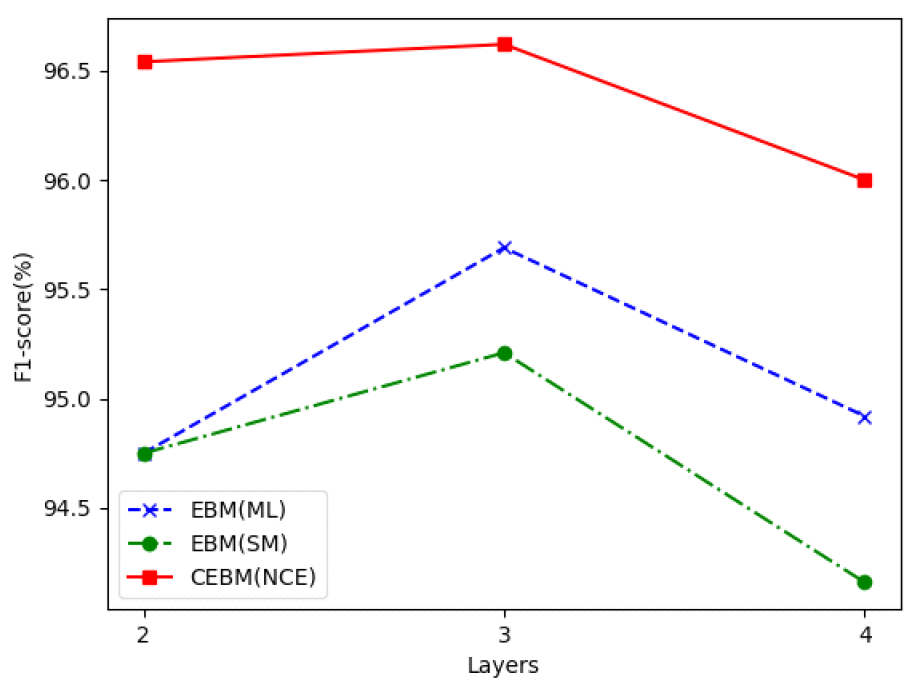 표(Table) 1. ECG에서 NCE 기반 CEBM와 다른 기법들과의 이상 탐지 성능비교 (Comparison of anomaly detection performance with NCE-based CEBM and other techniques in ECG.)
3.2 UNSWUNSW NB15[20]는 최신 네트워크 트래픽 특성 과공격 기법을 반영한 네트워크 침입탐지를 위한 대표적인 데이터 셋이다. 이 데이터는 여러 개의 트래픽 생성 알고리즘을 통해 만들어진 가상의 네트워크 트래픽을 캡처하여 생성되었다. 데이터는 네트워크에서 발생할 수 있는 9개의 공격 유형과 1개의 정상 유형을 가지는 레이블로 구성되었다. 이상탐지를 위해 9개의 공격 유형은 ‘1’로, 정상은 ‘0’으로 표시되었다. 각 네트워크 데이터는 42개의 특성을 포함한다. 42개의 특성은 네트워크의 특징을 나타내는 연속적인 값과 이산적인 값으로 구성되었다. 이 특성들을 신경망의 입력으로 사용하기 위해 188개의 특징 벡터값을 갖도록 변환되었다. 최종적으로 모든 데이터에 대해 [0,1] 사이로 minmax 정규화로 전처리되었다. 학습에는 정상 56,000개, 테스트는 82,332개(정상: 37,000, 비정상: 45,332)를 사용하였다. 학습을 위한 하이퍼파라미터는 ECG와 비슷하게 설정되었다. [TeX:] $$D_\theta(x)$$와 [TeX:] $$G_\phi(x)$$의 신경망은 3층으로 구성하였고, (188-512-512-1)와 (188-512-512-256)의 노드 수를 각각 사용하였다. 성능 비교를 위해 AE, ML 및 SM EBM 그리고 최근에 제안된 침입탐지를 위한 federated learning with autoencoder (FLAE)[25]와 비교하였다. 표 2는 UNSW에서 제안된 기법과 다른 기법들과의 이상탐지 성능을 비교하였다. ECG와 마찬가지로 AE, ML 및 SM 기반 EBM 보다 제안된 모델이 더 높은 F1-score를 나타내었다. 또한 최근에 제안된 FLAE의 83.63%보다 더 높은 86.73%의 성능을 나타내었다. 이때 CEBM의 precision과 recall은 각각 96.10%와 79.02%를 나타내었다. 따라서 UNSW 데이터 셋과 같은 네트워크 이상탐지 실험에서도 제안된 기법이 매우 효과적임을 알 수 있다. 표(Table) 2. UNSW에서 NCE 기반 CEBM와 다른 기법들과의 이상탐지 성능비교 (Comparison of anomaly detection performance with NCE-based CEBM and other techniques in UNSW.)
3.3 MNIST/Fashion-MNISTMNIST[21]와 Fashion-MNIST[22]는 28x28 크기의 gray 이미지로 각각 10개의 클래스를 갖는 데이터 세트이다. MNIST를 정상 데이터로, Fashion MNIST를 이상 데이터로 하는 이미지에 대한 이상탐지 실험을 수행하였다. 학습에는 정상으로 MNIST 60,000개의 훈련 데이터를, 테스트에는 정상과 비정상으로 각각 MNIST와 Fashion-MNIST 테스트 데이터 셋 10,000개씩을 사용하였다. 학습을 위한 하이퍼파라미터는 ECG와 같고, SGLD 파라미터로 γ=0.01를 사용하였다. CEBM의 [TeX:] $$D_\theta(x)$$와 [TeX:] $$G_\phi(x)$$의 신경망은 3층 FCNN 형태로, 각각 (784-1024-1024-1)와 (784-1024-1024-512)를 사용하였다. 표 3은 제안된 CEBM과 다른 기법들과의 성능을 나타낸다. AE에 비해 ML과 SM 기반 EBM이 더 높은 성능을 나타내었고, ML EBM이 98.38%로 SM보다 더 뛰어난 성능을 보였다. 제안된 CEBM은 99.32%로 다른 기법들에 비해 더 뛰어난 F1-score를 나타내었다. 이때 precision/recall은 98.91%/99.74%이다. 따라서 MNIST/Fashion-MNIST와 같은 이미지 이상탐지 실험에서도 제안된 CEBM이 다른 기법에 비해 더 효과적임을 알 수 있다. Ⅳ. 결 론본 논문에서는 두 개의 비정규화된 에너지 함수로 구성된 확률분포의 곱으로 새로운 CEBM 구조를 제안하였다. CEBM을 NCE 기법으로 학습하기 위해 하나의 분포를 잡음분포로 사용하였고 이를 위한 목적함수를 유도하였다. 제안된 목적함수를 위해 잡음분포로부터 데이터를 생성하기 위한 근사적인 1-step SGLD에 기반한 샘플링 기법을 제시하였다. 제안된 NCE 기반 CEBM의 성능을 평가하기 위해 3가지 데이터 세트, ECG, UNSW 그리고 MNIST/Fashion-MNIST에 대한 이상탐지 실험을 수행하였다. 모든 데이터 세트에서 기존의 AE, ML과 SM 기반의 EBM에 비해 제안된 CEBM이 더 높은 F1-score를 나타내었다. 따라서 제안된 CEBM 기반 NCE 학습방법은 이상탐지에 매우 효과적임을 나타내었다. 향후 연구 방향은 먼저 대용량의 고차원 데이터에 대한 CEBM의 특성을 파악하고 이를 이상탐지에 적용하는 것이 필요하다. 그리고 텍스트와 같이 순차적인 특징을 갖는 데이터에 대한 이상탐지를 위해 FCNN 대신 transformer와 같은 구조를 포함한 CEBM에 대한 연구가 필요하다. BiographyReferences
|
StatisticsCite this articleIEEE StyleD. K. Kim, "Noise Contrastive Estimation of Coupled Energy-Based Model for Anomaly Detection," The Journal of Korean Institute of Communications and Information Sciences, vol. 50, no. 10, pp. 1497-1504, 2025. DOI: 10.7840/kics.2025.50.10.1497.
ACM Style Dong Kook Kim. 2025. Noise Contrastive Estimation of Coupled Energy-Based Model for Anomaly Detection. The Journal of Korean Institute of Communications and Information Sciences, 50, 10, (2025), 1497-1504. DOI: 10.7840/kics.2025.50.10.1497.
KICS Style Dong Kook Kim, "Noise Contrastive Estimation of Coupled Energy-Based Model for Anomaly Detection," The Journal of Korean Institute of Communications and Information Sciences, vol. 50, no. 10, pp. 1497-1504, 10. 2025. (https://doi.org/10.7840/kics.2025.50.10.1497)
|

